
This article is by Jeremy Stanley, Chief Data Scientist and EVP Engineering at Sailthru, where he’s responsible for building intelligence into the company’s marketing personalization platform. His data science team works on algorithms for prediction, recommendations and optimization.
Data scientists are trained to handle uncertainty. The data we work with, no matter how “big” it may be, remains a finite sample riddled with potential biases. Our models tread the fine line between being too simple to be meaningful and too complex to be trusted. Armed with methodologies to control for noise in our data, we simulate, test and validate everything we can. A great data scientist develops a healthy skepticism of their data, their methods and their conclusions.
Then, one day, a data scientist is promoted and presented with an entirely new challenge: Evaluating a candidate to become a member of their team. The sample size drops fast, experimentation seems impractical, and the biases in interviewing are orders of magnitude more obvious than those we carefully control for in our work.
Many data science leaders resort to following traditional hiring practices — but they shouldn’t.
In setting out to build my latest team, I spoke with many data science leaders to gather their ideas and best practices. I was especially influenced by the ideas of Riley Newman, Head of Data Science at Airbnb, who designed and implemented a radically different way of recruiting data science talent, and who I spoke to several times while devising the system I'll share with you here. I also learned a great deal from Drew Conway at Project Florida, who has continually evolved his hiring process to select for talent that could squarely land in the middle of his famed data science venn diagram:
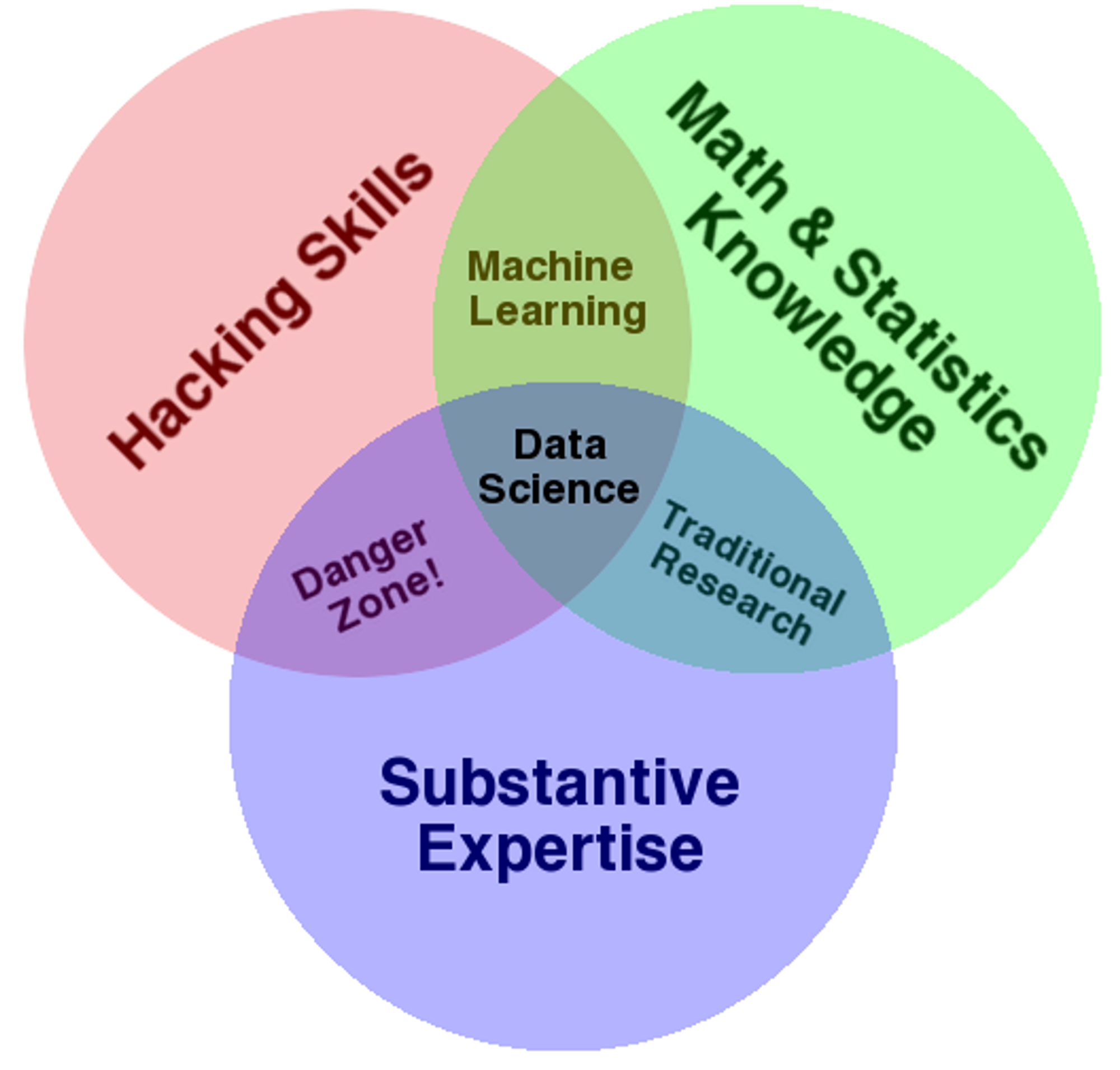
In this article, I will outline the goals of a new process that Riley developed and I adapted based on this research, describe its underlying principles, and walk through the implementation we have experimented with at Sailthru. And of course, this guide wouldn’t be complete without looking ahead at opportunities to adapt and improve the process even further.
How to Start a Recruiting Revolution
In developing our recruiting process, we set out to improve the following measurable objectives:
- Accuracy: Maximize the chances that new hires will become exceptional employees.
- Loss: Minimize the chances that great prospects leave the hiring funnel early.
- Success: Maximize the chance that offers will be accepted.
- Effort: Minimize the long-term distraction to the hiring team.
At first glance, any experienced manager would think that it’s impossible to improve all four of the above goals simultaneously. The first three tend to work against each other in practice (e.g., the greater the candidate, the harder it is to get them to accept an offer). Beyond that, improving them all would seem to dictate greater ongoing effort by the team.
In a traditional hiring process, most managers feel fortunate if their accuracy is as high as 50%. That is, no more than half of their hires turn out to be exceptional. Loss is hard to measure (after all, candidates who fall out of the process didn’t come to work for you), and most managers worry that they regularly lose amazing talent because their process is so long and cumbersome.
In a competitive field like data science, strong candidates often receive 3 or more offers, so success rates are commonly below 50%.
And the ongoing effort that hiring requires can easily consume 20% or more of a data science team’s time.
After validating this experience with other data science leaders, I sought to implement a process that could achieve the following:
- Accuracy: 90% of hires should in fact be exceptional employees.
- Loss: We should make offers to 80% of the great candidates who enter our funnel.
- Success: 65% of offers extended should be accepted.
- Effort: Hiring should consume less than 10% of the team's time.
By designing a hiring process that is smarter — both in identifying great candidates and simultaneously reducing the risk of losing them — it’s possible to improve on the first three goals simultaneously. And, by investing heavily upfront (an investment that pays off handsomely over time), the ongoing effort and distraction to the team can be managed.
To ensure that we met our objectives, we developed a set of core principles that can be applied to hiring for any function. Principles that keep everyone focused and aligned can significantly help any big process change. They also serve as a healthy foundation when you iterate on that process. Here they are:
Ensure your hiring process is always on and continually improving.
It’s common to think about hiring as either a task that you occasionally participate in, or as a blitzkrieg campaign that is periodically all-consuming. Instead, architect your hiring process to be an engine that is always on, with a predictable funnel of talent moving through clear stages. This ensures that you’re always recruiting, and that whenever great talent comes to the market, you’ll have the opportunity to engage.
Investing in an always-on process will force you to treat hiring as a discipline. This will drive consistency in protocol and results, enable you to collect data about your successes and failures, and force you to manage your talent pipeline with the same care you manage your data pipelines.
Make your process mirror the reality of your hiring needs.
The brutal truth: Standard interviewing questions are fatally flawed.
Ask candidates about their prior experience, and you'll discover whether they can articulate what happened around them at other jobs. Ask them technical questions, and you’ll uncover their ability to regurgitate knowledge. Make them solve a 'toy' problem on a white board, and you’ll discover how quickly they solve toy problems. A candidate that passes all of these hurdles with flying colors may be a completely ineffective data scientist in practice.
To address these flaws, you must first have a very clear understanding of how you want candidates to perform data science. At the highest level, you should be clear on the end product your team will produce. Will it be visualizations and analyses that inform decision makers? Designs and prototypes that are given to developers? Or applications that can be scaled and supported in production environments?
Next, you should have a clear understanding of what you want successful candidates to do. Identify five opportunities you would love to see a data scientist tackle. For each, ensure that you have (or could reasonably collect) the data required, and can envision a solution that would be effective even if you couldn’t design it yourself. These opportunities lie at the intersection of the near-term strategy of your company, the feasibility of how your organization or product functions, and the constraints of the data that you currently have or can reasonably generate.
Knowing answers to how your team performs data science and what challenges you most want candidates to be able to handle, you can design a hiring process that closely reflects your working conditions. This means you should put candidates into an environment that closely resembles what their ‘day-to-day’ would be. If they can succeed in that environment during the interview process, then their chances of succeeding long-term are much greater.
Run objective evaluations first to minimize your biases.
Candidates who would be top performers may fail a traditional interview process.
The culprit is interviewer bias. As soon as you enter the room with a candidate, you begin forming opinions (mostly unconscious) about their abilities. There are a wide array of such biases (check out the list of 100+ cognitive biases here), but the most common bias in interviewing is to prefer people who are similar to ourselves.
Great data scientists must have very strong quantitative and programming skills. That’s non-negotiable. So we designed our process to test these skills first, then move on to more subjective (yet still measurable) skills like problem solving and communication. Only at the end do we get to the most subjective of all — how the candidate works on a team and fits into the culture.
These later stage, more subjective criteria are the most time-consuming to evaluate and are where biases are most likely to creep in. Moving them late in the funnel has the combined benefit of reducing the load on the team (we don’t evaluate culture fit until we’re confident they have the skills we need) and minimizing the risk of losing a great candidate prematurely.
Design your process to sell the candidate.
Most interviewing processes also fail to sell the highest-quality candidates on the role. Interviews are stressful at best and mundane and tedious at worst. Candidates are often forced to repeat their story to 4 or more interviewers and answer questions for hours on end. Afterward, while they may have been able to ask a few questions of their own, they often struggle to imagine what it would be like to work at the company. They then wait for days to receive feedback that is rarely honest or prompt. So how do you fix something so broken?
Create a process where you give candidates the data and problems that reflect the real challenges they’ll face at your organization. On top of that, ensure that your hiring process engages the candidate with your team’s dynamic and culture so that they get a real taste of what it would actually be like to work with you. Each of these candidates should complete the interview process with a trusting sense of what it would be like to join your team.
Make smart decisions with your team, not in your tower.
No matter how you hire, every manager has to make difficult decisions. To decide with confidence, establish clear frameworks for evaluating candidates at every stage of your funnel. This includes defining objectives and metrics that everyone on your team understands.
Also, make decisions openly as a team. This ensures the hiring manager hears direct feedback about candidates from everyone involved in the process. Even more importantly, it makes sure that you’re all looking for the same qualities. An open forum helps to change your recruiting needs and strategy over time.
Finally, engage your cross-functional partners in evaluating your candidates. Data science is never truly done in a vacuum. You will collaborate with decision-makers, engineers, and product managers. Involve key partners in those areas so you select talent that can be successful across departments and divides.
Move faster than the market.
The market for great data science talent is incredibly competitive, so your process should ensure that you move candidates through your funnel as quickly as possible, keeping momentum high and minimizing the chance that they accept a competing offer. Moving fast requires a streamlined process that allows you to build confidence as well as speed. Invest in tools and logistics to track how long candidates stay in each stage of your funnel and aggressively change your system to gain keep your edge.
The Implementation Game
In the movie The Imitation Game, Alan Turing’s management skills nearly derail the British counter-intelligence effort to crack the German Enigma encryption machine. By the time he realized he needed help, he’d already alienated the team at Bletchley Park. However, in a moment of brilliance characteristic of the famed computer scientist, Turing developed a radically different way to recruit new team members.
To build out his team, Turing begins his search for new talent by publishing a crossword puzzle in The London Daily Telegraph inviting anyone who could complete the puzzle in less than 12 minutes to apply for a mystery position. Successful candidates were assembled in a room and given a timed test that challenged their mathematical and problem solving skills in a controlled environment. At the end of this test, Turing made offers to two out of around 30 candidates who performed best.
There’s a lot to learn from this anecdote.
The process ensured that Turing had cast the widest possible net for available talent, attracted them with a challenging problem and intriguing offer for employment, and then validated their skill in a controlled environment. In an apocryphal turn of events in the movie, one of the candidates Turing recruited was a woman named Joan Clarke, who became a very close collaborator. Joan was incredibly talented, but given the biases of the time, would almost certainly have been overlooked for a role on a code-breaking team had it not been for Turing’s scientific approach to hiring.
Just like in The Imitation Game, we put candidates through a sequence of experiences that approximate their potential working environment and evaluate their skills on problems that are highly predictive of their success once we hire them. Surprisingly, with the right planning and investment upfront, this can be done even more efficiently than in traditional interviews, and spare your team’s time.
At the highest level, this interviewing process has two key components:
- Take-home test: A short exercise that tests a candidate’s ability to solve a series of increasingly difficult challenges.
- Data Day: A full day spent working beside the team on a more open-ended challenge, concluding with a presentation of their work to a group.
We manage this process as a funnel. Of 500 inbound applicants, 250 (50%) will submit a take-home test, 25 (10%) will pass, 20 (80%) will come to the data day, 4 (20%) will pass the Data Day, and then 3 (75%) will accept the offer. That means in order to find a single great hire, we need over 150 applicants.
The key levers to pull here are (A) the quality of the applicants in the funnel, (B) the success rates in submission of take-home tests and attending a Data Day, and (C) the accuracy of the take-home test and Data Day filters. By tracking your candidates through this funnel and examining the loss at each stage by channel (e.g. where they came from), you can begin to identify higher performing channels, and the stages in your funnel that are filtering too aggressively.
Given our four distinct goals — to maximize accuracy (hire exceptional employees) and success (ensure they accept offers), while minimizing loss (candidates abandoning early) and effort (team distraction) — we invested a significant amount of time in designing a clear and efficient process that is data driven and appealing to candidates.
This process has the following six stages, which move from easiest and most objective to most difficult and subjective:
- Pre-screen: Check for a pulse
- Take-home test: Test for sufficient skill
- Sales pitch: Convince them to come to the ‘data day’
- Data day: Test competence in a realistic, controlled environment and evaluate culture
- Decision: Make a quick and definitive decision
- Communicate: Follow up with every data day candidate
Let’s take a more in-depth, tactical look at each phase.
1. Pre-screen
Note, at Sailthru we don’t pre-screen data science candidates at all. We don’t have to review their resume or debate their experience or qualifications.
If they have a pulse (and an e-mail address) we give them the take-home test.
It's our version of The Imitation Game crossword. This saves significant time and energy and allows you to engage with promising candidates faster.
But the most important reason not to pre-screen is that it removes a huge source of initial bias. Many incredibly talented candidates won’t have the education or experience recruiters are trained to look for. This not only means you lose out on great candidates, but you’re also going to be competing furiously for those few candidates that look good on paper — everyone else wants them too.
2. Take-home test
The take-home test is incredibly important. It’s the first line of defense in filtering out candidates and requires the most work from your team given the volume of potential submissions. It’s also the first time candidates will get a sense of what your team does.
This stage is not only a critical hurdle to prevent you from wasting time on unqualified candidates, but also an extremely important part of selling candidates on the role. For all these reasons, you should continuously evolve this stage of your process as you gather data on candidate performance and interest through your funnel.
A sound take-home test should have the following attributes:
- Self-explanatory - You want to minimize the chances that a candidate will have questions or need clarification.
- Bounded - It should take no more than 2 hours for a skilled candidate to complete.
- Desensitized - It will be distributed widely, so don’t include any proprietary or sensitive data.
- Relevant - Match the problems to the top challenges you actually face in your job.
- Direct - Be clear about exactly how you want the test answered and how you will evaluate the performance of candidates.
- Gradated - Ask increasingly difficult questions so you can easily tell the candidate’s real skill level.
To design your take-home test, first start with the most pressing problems you want your existing data science team to address. Of those problems, pick one or two that you (A) have or can fabricate compelling data for, (B) will be fun for candidates to solve, and (C) can be simplified (perhaps grossly) to something that could be addressed by a very strong candidate in under 2 hours.
After you'venarrowed the problem space, compile the data needed to answer your take-home questions. Ideally, this is data that comes from your production environment and is sufficiently cleaned, permuted or aggregated so as to be harmless were it to fall into anyone’s hands (assume it eventually will).
Alternatively, you can construct entirely fake data, but be careful as many of the challenges in data science arise from dealing with inconsistencies and outliers. I would recommend providing around 1 million rows of data (and possibly multiple files) — enough to require some attention to the performance of code used without being burdensome.
Once you have assembled the data, craft 2-3 very clear questions that escalate in difficulty and have definitive, measurable answers. Ensure that your questions will test not only the candidate’s ability to manipulate the data, but also their ability to think logically about the analysis and interpret results from any models built.
Given the assembled data and selected questions, draft instructions. This should be a short, easy-to-read document that describes the data provided and contains the final questions. Additionally, you should instruct the candidates on how much time they should use, not to force them to bound their time, but to indicate how much time you’re estimating so they don’t spend days on a task that ought to take hours.
Most importantly, include a section devoted to how you would like candidates to answer the questions. What tools would you prefer them to use? How would you like them to submit their answers? What are you looking for in terms of quality of code? Are visualizations or interpretations important to you? Be careful what you ask for here. It’s a key opportunity for you to sell yourself and the organization.
Next, give the take-home test to your other team members or to friends in the community. Use this to calibrate the test and ensure that you have consesus on the definitive answers. The last thing you want is for candidates to struggle with ambiguity.
Finally, establish a clear framework for evaluating submissions. Consider these criteria:
- Correctness - Did they get the correct final answers?
- Logic - Was the logic in their answer sound?
- Assumptions - Did they make any assumptions clear?
- Code quality - Is the code executable, tested, functional, documented?
- Efficiency - Is the code concise and reasonably performant?
- Technology used - Are they using modern tools and libraries appropriately?
- Communication - Were answers clear and presented in a reasonable way?
3. Sales Pitch
Once a candidate has passed your take-home test, your next challenge is to convince them to come to your “Data Day” interview. Most will be expecting a traditional interview where they spend no more than 4 hours at your office — certainly not the whole day. It’s imperative that you convince them that it’s worth their time.
The critical parts of your sales pitch are how you connect with the candidate, how you articulate the exciting opportunity you are presenting, and how you describe and prepare them for the Data Day. It should all be geared toward building their interest and enthusiasm — this is not the time for you to evaluate them.
Every candidate is motivated by different factors, so it’s crucial for you to listen carefully and direct the conversation to the topics they care about most. In my experience, I have found the following to be key motivators:
- The overall potential for the product and company.
- How data science is organized, where it reports, and what impact it has had to date.
- The key challenges or opportunities data science will be working on in the near future.
- How data science works cross-functionally with other teams.
- The scope, size and quality of data available, and opportunities for future collection.
- How the team manages their work and collaborates in priorities and decisions.
- The specific tools and technologies that the team uses.
Ultimately, you will find candidates who are unable or unwilling to schedule a data day. In the end, while that may mean that you miss out, you have to be willing to take that risk.
The 'Data Day' becomes a gold standard by which you will evaluate all candidates.
4. Data Day
The Data Day itself is in many ways the heart of this recruiting process. Done well, it encapsulates the final technical, strategic and skill evaluation of a candidate with an analysis of his/her cultural fit in an experience that really “sells” them on your team and company. With enough preparation, this can be accomplished with no more time commitment from you or your team than would be required by a traditional interview.
The prep checklist includes:
- Instructions: A clear and concise document that describes the day’s challenge, the data and evaluation criteria, and everything else a candidate needs to know to be successful.
- Data: A rich extract of production data that will challenge and inspire your candidates. A great data scientist should be able to spend a week with this data without getting bored.
- Laptop: A new and powerful laptop that would be identical to what they would work with that has all data and applications they need pre-installed.
Preparation is critical to a successful Data Day. By ensuring the candidates have everything they need to be productive, you can maximize the time they have to accomplish meaningful work.
Instructions
When a candidate arrives for their data day, the first thing you should provide is a printed set of instructions. The sections to consider including (as concisely as possible) are:
Introduction -
A quick welcome and introduction to the day's schedule and task.
Disclaimer (perhaps an NDA) -
Consult with your legal department on whether a disclaimer is required.
Goals -
A high-level overview of the task at hand and what you're looking for in a successful Data Day.
Suggested Timeline -
How you would imagine a candidate would use their time. Make it clear that the biggest challenge they will have is running out of time.
Data -
A broad description of the data you have provided, just enough to give them context for the following sections.
Topics -
A concise list of 4 or 5 topics to consider pursuing (more on how to choose these later).
Evaluation -
What you're looking for from successful candidates.
Technical Setup -
A brief explanation of the tools provided on the laptop.
Data Details -
A more thorough description of the data provided. For each file, describe the contents as a whole, each field included, and the size (number of rows or observations) in the dataset.
The most important thing is the selection of topics. These should be diverse enough that candidates with varied backgrounds will find something that both interests them and is approachable. At the same time, be sure to keep the topics focused on applications that would be valuable for your business. That ensures that you’re testing for skills that you need, and gives the candidate a more realistic sense of what they would be doing on your team.
Finally, the topics should be presented as suggestions. I prefer to give candidates free reign here. In the end, what’s most important is that they feel confident that they can produce a meaningful analysis and demo by the end of the day.
Keep in mind, you will spend far less time answering questions from candidates if your instructions are clear and to the point.
The Data
The next consideration is the data candidates will use. This dataset should differ from the take-home dataset in two ways. First, it will not be distributed widely, so you should absolutely use production data. But remember that while candidates will be using a laptop that you provide, they will have internet connectivity, so you cannot guarantee total control of the dataset. As such, ensure that there is no personally identifiable or strategically important data included.
Second, this dataset should be large and rich. You can include more observations, multiple sets of data, complex time series and a diverse array of data points about each observation. One of the key challenges of a Data Day is requiring the candidate to take a “real world” set of data and identify a practical analysis or modeling path. This often requires ignoring large amounts of available data, or significantly simplifying the data through filtering or aggregation.
In the end, it will ideally surprise you how the strongest candidates use what you provide.
An important consideration is how much you should preprocess the data in advance. In general, unless you specifically want to test for their ability to cleanse very messy data, I would suggest keeping this sample reasonably clean to ensure that they don’t waste valuable hours on munging that would otherwise have gone into analysis or modeling.
Laptop
Provide the candidate with a laptop that has the instructions, data and software all in one accessible place. At Sailthru, we use a MacBook Pro (all data scientists and engineers use Mac or Linux machines), and we install the following software:
With HomeBrew, a data scientist can quickly install other software as needed. Further, we place the data in CSV files in their home directory. We suggest to candidates that they submit their take-home test using an open source scripting language (like Python, R or Julia) so that everyone is comfortable with it.
Schedule
The schedule for a typical Data Day at Sailthru looks like this:
10 a.m. - Welcome
The candidate arrives and is greeted by our recruiter and shown to a designated spot next to the team.
10:05 a.m. - Buddy
The candidate’s buddy (an assigned member of our data science team) takes the candidate for coffee and shows her or him around the office.
10:15 a.m. - Orientation
The buddy gives the candidate instructions for the day along with the interview laptop and brief instructions on where to find the data.
10:20 a.m. - Direction
The candidate sits down to read the instructions and examine the data, and typically decides on a direction to pursue.
11:30 a.m. - Stand up
The candidate listens in on the daily team stand up meeting to gain insight into what he or she will be working on, and is asked to speak to the chosen direction he or she is pursuing.
12:30 p.m. - Lunch
A few members of the team take the candidate out to lunch, learns more about his/her background and personality, and lets the candidate ask any questions.
As needed - Questions
The candidate may ask data, technical or contextual questions of anyone on the team, but often starts with their “buddy” if available.
4:30 p.m. - Reminder
We remind the candidate that he/she will be presenting at 5:30, and encourage them to begin working on their demo.
5:30 p.m. - Presentation
The candidate presents for 20 minutes on what he/she found or built during the day, followed by 10 minutes of rich Q&A with the team and other attendees.
6 p.m. - Feedback
We ask the candidate to give us feedback on his/her experience. Then the buddy or recruiter directs the candidate out and sets expectations for when we will communicate a decision.
6:15 p.m. - Decision
The team finishes their discussion of the candidate, and 90% of the time a decision has been made.
Overall, the time commitment from the team is quite reasonable. The buddy spends 15 minutes in the morning and maybe another 15 minutes in the afternoon answering questions. The stand up and lunch were going to happen regardless. The presentation and Q&A take 30 minutes for a group of five participants, and then the decision typically takes another 15 minutes afterward. In total, the team spends just over 4 person-hours with the candidate, no more than would be spent in a minimalist traditional interview.
By far the most insightful part of the day from a culture fit perspective is the lunch, where you get to see how the candidates act in an informal, social setting.
The most insightful part of the day from a technical perspective is the Q&A after the presentation, where we try to ask probing and challenging questions in order to validate the rigor of the candidates’ approach and determine how they engage in spirited technical or analytical debates that are common on our team.
Lessons Learned
The Data Day should be a reflection of your team and your company, so you should adapt the process to suit your specific needs. We make a point to ask candidates for feedback at the end of the day, and have already made numerous changes based on their input. Here are some of the best lessons we learned:
- Candidates almost always run out of time. Encourage them to pick a direction they’re confident in and take an iterative approach to their work. That way, if their approach doesn’t work out well, they have plenty of time to adapt. Further, stress that an inconclusive analysis well presented is far better than a definitive analysis reached tenuously.
- Don’t let lunch run too long. The candidates have a limited amount of time to work, and after 45 minutes will begin to worry about getting back to it in order to finish in time to present.
- Invite a diverse group to the presentation. Anyone that you think the candidate would interact with on a regular basis should be there. This gives you the opportunity to solicit their feedback about the individual’s work and communication style, and gives your candidate a better sense of the key internal relationships.
- Be transparent with candidates about what Data Day entails before they arrive. That way they have time to mentally prepare for the experience, which relieves the stress of the day.
5. Decision
We evaluate candidates based on the following dimensions at Sailthru:
1. Problem structuring
How did you structure the problem, what assumptions did you make and how did you narrow the scope?
2. Technical rigor
How reliable, readable and flexible was the code that you developed to accomplish your work? How scalable would the approach be?
3. Analytical rigor
How logically sound, complete and meaningful was the approach (machine learning, statistics, analytics, visualization) that you applied?
4. Communication
How clearly were you able to describe your work, approach, methodology and conclusions? How effectively did you answer questions?
5. Usefulness
If made production-worthy, how useful would the results of your work be to Sailthru?
We include these criteria in the Data Day instructions so that candidates know what success looks like.
After candidates complete their presentation and Q&A, their buddy shows them out of the office. Then we immediately begin discussing the candidate while everyone’s impressions are fresh. We give each participant a chance to share feedback on the above criteria (if they have an opinion), starting with people outside our team first. Then the least experienced members of our team speak, followed by the most experienced. This helps prevent the team or the leader from biasing the opinions of others in the room in advance.
In general, if any participant is a strong 'no' on the candidate, that’s reason enough to reject them.
This rarely happens for technical reasons (the take-home test should qualify most candidates to be reasonably productive). But when it does, you should carefully re-evaluate your test to ensure it’s effectively screening candidates.
When this happens for culture fit or communication reasons, it’s critical to discuss the issue openly. That helps establish and reinforce a healthy norm for how your team wants to behave, and reduces the risk of succumbing to one individual’s biases.
If everyone is lukewarm about a candidate, that is also an obvious “no.” Often this is due to limitations in their work — how much they accomplished, the rigor in their thinking, or their technical execution. If an impasse remains, then either the team leader should make a final decision (err on the side of rejection), or in rare cases, you may want to invite the candidate back for further discussion.
6. Communication
The final stage of the process is to communicate the outcome to the candidate. Those who fail the take-home test hear back from our recruiter. We would love to give every submission direct feedback, but it’s impractical given the scale of the number of submissions we review.
That said, a member of the data science team follows up with every candidate that does not receive an offer after coming in for a data day. This ensures that these candidates receive constructive feedback and can learn more from the experience.
Ultimately, we’re excited about the potential of every Data Day candidate and want to both be respectful of their time and stay connected in case our paths cross again. Data science is a small community.

Challenges and Future Opportunities
Hiring great data scientists is difficult, and while I’m convinced that this process has had a tremendously positive impact on our hiring at Sailthru, I also believe we have much more to learn. Here’s a taste of what we continue to wrestle with.
Minimizing False Negatives
Our process may generate too many false negatives — i.e. candidates who are well suited to data science but who do not receive an offer. The greatest source likely occurs at the take-home test stage, where candidates may not be willing to invest the time to complete the test. Making the test easier to complete for talented candidates and improving the brand of our organization in the community are both steps we can take. Ultimately, this is a question of pipeline development, and is problematic insofar as it slows your ability to hire the highest-caliber talent.
Passing on strong candidates who struggle during a Data Day is far more concerning, as these candidates have invested in us, and we have invested in them. This happens for several reasons, but the most common is that the Data Day is a high-pressure environment. Candidates must learn a new dataset, frame a problem, develop a solution and craft a presentation all in the course of 8 hours.
While some candidates excel under this pressure, others become overwhelmed, and are unable to demonstrate to us what they would normally be able to accomplish. Unfortunately, we’re unable to account for this in our decision making, as it’s nearly impossible to tell this apart from inability or inefficiency, both of which we aggressively select against.
Another reason candidates may not succeed during a Data Day is that they are unfamiliar with the tools. They may have more experience with proprietary or commercial tools, or with another operating system. This could be alleviated by securing licenses for more commercial software and offering the use of Windows on a virtual machine. Those options come with significant cash and operational costs. Also, familiarity with a Linux operating environment and open source tools is a requirement we feel strongly about.
Getting Started
Arguably one of the most challenging aspects of this process is getting it up and running. Many organizations will struggle with this if they don’t have a solid team in place already that can adapt, execute and optimize this process.
Further, this system takes collaboration between the data science team and the recruiting team. Both must be convinced it’s worth the investment and continuing evolution, or it will be impossible to implement well and maintain over time.
Tailoring This Process for Other Functions
At Sailthru, we’re actively working to mold this process for additional departments, like software development. The structure of the process can remain largely the same while the specific challenges offered can vary.
For example, for developers, you can provide a clean Github repo and ask that they build a simple application given clear requirements and acceptance criteria. This provides the opportunity to see not only how they architect and code an application, but also how they develop their software (e.g., test-driven development) and how they document their implementation.
Alternatively, you can take a part of your existing application, simplify it to something that can be easily run by the developer, remove a specific feature and then ask them to re-code it. This allows you to see how they work with your existing code, and you already have a clear benchmark for how the feature should be implemented.
The Takeaways
This hiring process has been truly revolutionary for the data science team I lead. We’ve passed on candidates who seemed perfect on paper and in conversation, but were unable to structure open-ended data problems or defend their analytical choices.
We’ve hired candidates we might never have before.
For example, in the past, I had screened out almost any candidate without a few years of prior work experience for fear that they would be too academically-minded. But using this process, we hired a data scientist with no more than a quantitative PhD and a few internships because he demonstrated outstanding practical skill during his Data Day. He started pushing changes to production in his first two weeks and has had a tremendously positive impact in his first three months.
What I’ve valued the most about this process, however, is that it removes a tremendous amount of doubt and uncertainty from our decision making. Hiring is one of the most important decisions we make as managers, and it feels wonderful to make those calls with confidence supported by clear evidence.
When we find a promising candidate, we can move quickly knowing that we have sold the candidate on our organization and team, and are positioned to win in an aggressive hiring market. As an extra benefit, we’re able to hire many people who go on to make a huge difference for the company without always competing for the candidates that everyone agrees look best on paper.
Invest the time and energy in building an always-on process that moves swiftly with certainty and selects for candidates who will excel at tackling your real challenges and opportunities.
Then stop worrying about hiring and get back to doing great data science.