
AI tools are changing the entire process of product-building, where people of all skill levels can turn an idea into something that actually works — something they can see, feel, interact with and iterate on. As Apple engineering leader Michael Lopp says, democratization is a good thing because it makes this capability available to anyone, but it also makes for an extremely crowded market.
What’s that mean for builders who want to create a standout product? Maybe taste matters more than ever. Or maybe it’s speed.
Figma’s newest tool, Figma Make, places human craft and creativity at the center of that product-building process. The company’s new prompt-to-functional-app experience that just launched at Config (along with three other products: Sites, Buzz and Draw) further blurs the line between design and production, reducing the technical skills required to actually bring a product to life.
David Kossnick, Figma’s Head of Product, AI, didn’t just make humans the focus of the product’s experience; they were also the focus of the product’s development, and specifically, its evaluation process.
Much like using an AI product, building an AI product requires a different approach. Unlike traditional software where there’s a clearer path to see what’s possible, the capabilities of an AI product exist in a foggy middle ground that’s only validated through actual testing.
Here on The Review, we’ve looked at a few of the different ways Figma makes decisions rooted in how real humans use its products. FigJam was born out of people in the community using Figma as a whiteboarding and brainstorming tool during the pandemic, according to the company’s CPO, Yuhki Yamashita. Figma Slides was a “bottoms-up project that came to life via a series of internal viral moments,” says its founding PM, Mihika Kapoor.
In this interview, we explore the evaluation process Kossnick and team used to launch Figma Make, one that kept humans at the center of every step — from defining success metrics, to the process for gathering qualitative feedback and then exploring how you can assess this data. If you’re interested in building, testing and validating AI products, this one is for you.
Developing the infrastructure shared by different AI products
Figma Sites was a massive infrastructure undertaking across the whole company, involving different rendering technologies, Kossnick says. But that’s the groundwork that made it possible to build Figma Make so quickly.
Sites allows you to publish a Figma design as a public website. To do this, Figma had to bridge the gap between design tools and web publishing — developing entirely new systems that could translate design elements into functional web code. Kossnick gives the example of converting a blue rectangle with specific dimensions in a design to HTML and CSS that browsers could render correctly. This was done by deterministic code-gen, not AI code-gen.
But as they were developing Sites, AI code-gen models were rapidly advancing. Then, a designer had an idea: What if, when you’re designing a static website, you could make these components functional with AI?
“That turned into a hackathon project and was extremely compelling,” says Kossnick. “It drew a ton of internal attention and excitement, people playing with it, showing examples. But it barely worked end-to-end. Failure rate was high. When it did work, it was incredible.”
This idea led the team to develop the second crucial pre-component of Figma Make — Code Layers in Figma Sites, which added three important capabilities. The first was making code a primitive on Figma’s canvas, allowing users to write code directly inside of Figma. The second was converting designs into code, and specifically React, not just HTML and CSS. And third, it created a chat interface where users could prompt to add coded interactions and behaviors. These innovations tackled some of the most difficult aspects of design-to-code conversion.
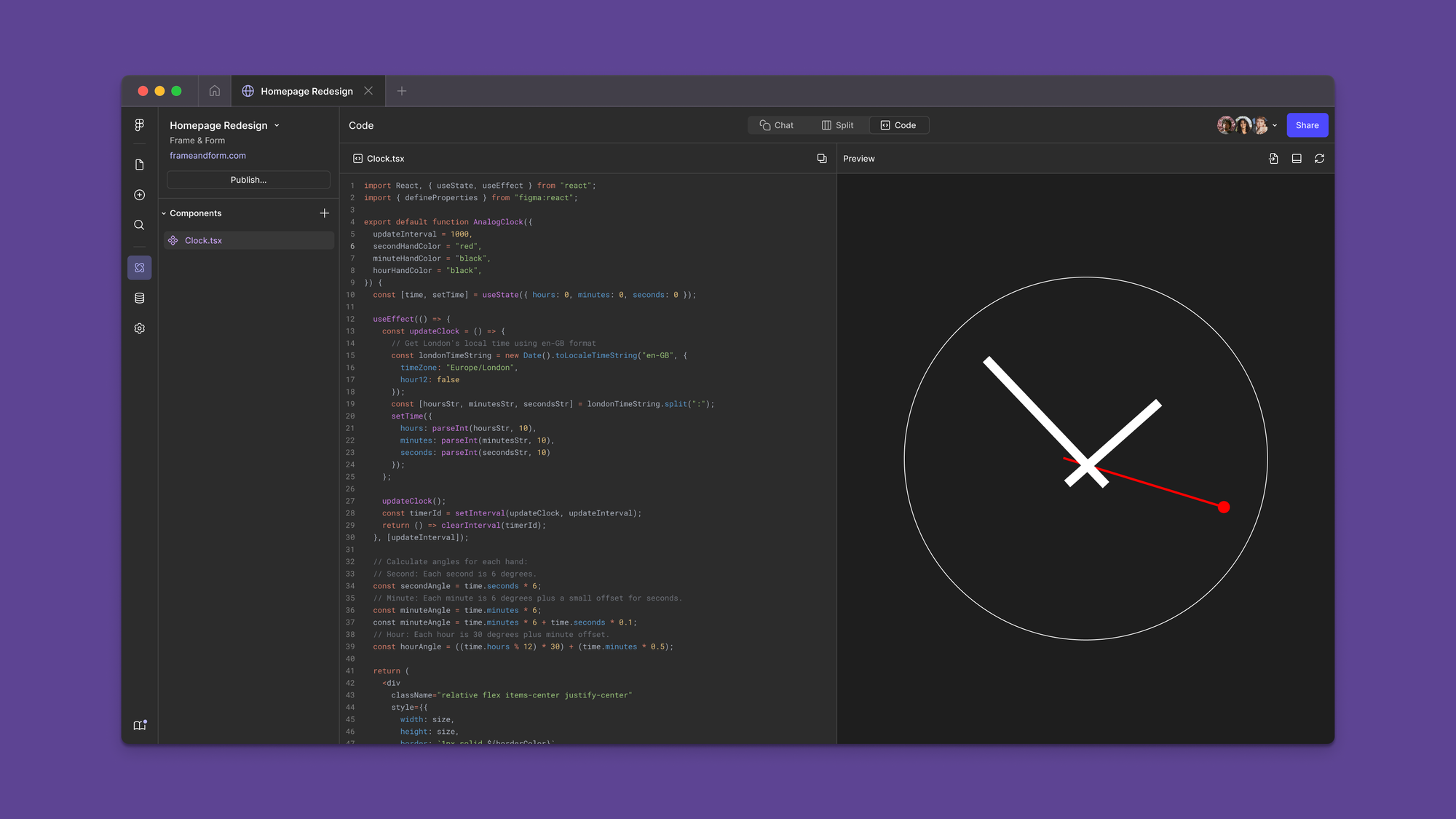
With this technology being tested internally, another hackathon led to the concept of Figma Make. A designer, tinkering on the side, created a standalone prototype of Code Layers as its own surface, where the interface lent itself to users asking AI to build a whole site or app, not just a component on a page. “It worked surprisingly well, a surprising percentage of the time,” Kossnick says.
We took the technology we’d been developing internally for something else and applied it to another form factor, another use case.
So, it worked (mostly). But was it actually viable as a product?
Figma’s decision tree to determine AI product viability
Kossnick says developing an AI product is difficult because of its malleability. “It’s easy to look at a product and imagine any part of the surface where AI could fit,” he says. “So deciding what not to do is really important.”
These are the four different paths for product development he uses to assess if allocating more time and resources into any AI project is worth it:
Path 1: The technology isn’t ready yet
“In AI product development, a prototype is becoming the gold standard as a validation mechanism before really starting on projects,” Kossnick says. This is especially true as the cost of prototyping has decreased tremendously.
Prototypes are the new PRD. We’re at the point now where it almost takes as much time to get to a prototype as it does to write a good PRD.
The first step is figuring out if the technology can actually support your idea, which can now happen very quickly and easily. Will the models be able to do it? Sometimes you have to wait until a new model drops.
“We’ve had projects where we started them, had a false start, and realized it was just too hard to build,” he says.
Path 2: It’s almost possible (with a lot of custom development)
This is really a consideration in how much work you’re willing to put into a project and its ability to scale.
“Maybe you can get there with clever prompting techniques, or maybe you end up fine-tuning or building a custom model,” says Kossnick. These projects require a whole different set of inputs to determine their success: the right staffing (e.g. modeling folks), training data sets, and more.
Path 3: It’s possible, but you need to adjust the product
The path here is a bit clearer if you’re able to ruthlessly prioritize and narrow scope. Ask yourself: how can I change the product in some way to make it easier for AI?
Path 4: It works
This is the happy path, where you’re striking the exact right intersection of technology and product capabilities.
Kossnick says builders need to ask themselves where they’re at in this decision tree. And once you’ve identified a path, speed is important — when prototyping happens fast, so can validation.
We took some of the earliest prototypes to users and got their feedback. The level of excitement on the vision was extremely high, and interestingly, from a wider set of personas than we anticipated.
Tips for constructing your AI product team
Each AI product has its own set of goals and constraints, which determine the structure of the team building it. Kossnick shares some of what he learned from staffing Figma Make:
- Role blending lets you keep the team small (even if you’re at a big company): AI tools bleed the stark lines in skillsets between different functions. Designers can code. PMs can prototype. Engineers can design. “A designer wrote the first system prompt for Figma Make,” he says. This has benefits for many reasons but the main one is that it’s easier to keep a team small, enabling you to move quickly.
- Almost everyone should be touching code: AI tooling makes this far more possible than it was years or even months ago. Getting everyone in the code creates a shared understanding around product functionality.
- Treat AI products as centralized teams: Code Layers and Make operated as one large integrated team sharing technologies and infrastructure with two different UX treatments. Builds can happen faster and when issues arise in the tech, fixing them is more streamlined.
- Get your target persona involved in the eval process: It was a conscious decision to have designers and PMs in the eval process because they’d be the ones using the product. Having their taste represented was important. “Garbage in, garbage out,” Kossnick says.
AI tooling is changing how all teams operate, not just engineering, product and design. But on the technical teams actually building AI products, embracing fluidity across roles allows processes to adapt to this new reality, resulting in greater pace and efficiency.
Figma’s three-step, human-centric eval process
Qualitative feedback is an important part of assessing traditional software, whether it’s user research programs or behavior tracking. Scaling these approaches can work for deterministic software where behavior is mostly predictable once coded. But AI products require a more continuous and widely-scoped approach to qualitative feedback — in large part due to the probabilistic nature of AI outputs and creative subjectivity in determining “good” performance.
Prototyping is so valuable here, especially when it’s increasingly more common, cheaper and expressive. It’s a tool to obtain feedback and sharpen a product quickly. “Continuous prototyping and refining enabled rapid validation,” says Kossnick.
Figma’s process for defining, obtaining and evaluating the product was rooted in what real people expected of it, how they used it and their quality assessment of its outputs. To use that human feedback — whether in the next prototype or the features that’d make it into the final version — Kossnick and his team had to figure out how to scale human taste while also making it actionable.
1. Define the success metrics that actually matter to your persona
Picking goal metrics is absolutely critical. As part of that, it’s important to have good coverage of classes and scenarios you care about (a mockup vs. a prompt, one shot vs. long shot conversion, desktop vs. mobile). “Every slice adds more scenarios to cover, so be rigorous about how many are core and in what order,” Kossnick says.
To determine what good looked and felt like, Kossnick considered three key elements of usability: the personas, the scenarios in which they’d use the product and which deliverables they expected.
But depending on your product or feature, these elements might hold vastly different weights. For example, Figma shipped AI text tools inside of Figma Design, and the team did very little custom quality work — instead mostly using the feature out of the box. “It was a case where users have more vanilla expectations,” Kossnick said. “There’s a question of what level of novelty vs. familiarity you’re leaning into, and what the quality bar is for the persona you’re picking to surface.”
For Figma Make, Kossnick used two key evaluation metrics: design score and functionality score, where each would be graded on a scale of 1 - 4:
- Design score: this assessed if, visually, the tool did what it was supposed to do. If you gave it a mock, did it create something that looked like the mock? If you gave it a prompt, and asked it to build something, did the thing look good? Would you actually use that thing?
- Functionality score: this assessed if the thing you created actually worked. It may not look polished, but specific, expected behaviors needed to be validated.
An evaluation of success has multiple facets. This is a piece that people often miss in doing evals — deciding what success means for their product.
You’ll notice both of these metrics were subjective and dependent on what the product actually delivered to the user — which means the evaluation process relied upon real product use cases to actually return valuable data.
When choosing your own evaluation metrics, Kossnick recommends thinking about how users will perceive the results of these metrics, and what orthogonal components of that assessment they’ll have. “The most important thing is humans, with taste, doing the evals in a way that’s aligned with what users will expect, on the right axis,” he says.
2. Gather qualitative, human feedback at scale
Toil away in the qualitative metrics all you want, but there’s no substitute for getting your product into the hands of people and seeing what they do with it, even (and especially) at the earliest possible stages.
Figma had four increasingly broadening concentric circles of user feedback as part of their eval process: the internal AI team building the product, the PM and design teams as target personas, the entire company to see what was possible, and an alpha group of customers for final viability assessments.
The first group of 30 people on the AI team received an “unoptimized prototype,” says Kossnick. “And we just saw what they wrote in it.”
At this point, there wasn’t a thumbs up or thumbs down feature in the product. But given the relatively small set of testers, the team could be scrappy. Designers, engineers and PMs on the AI team were asked to give their feedback in Slack — showing their prompt, a link to the thing they built, and the assigned design and functionality scores from 1-4. “In one day, we got hundreds of example prompts. We quickly learned there isn’t one quality bar,” Kossnick says.
While designers (quite obviously) cared about look and feel, all personas cared about look and functionality — they wanted to create mini apps that were usable enough. “It was helpful, early in the project, to see that there were different hills to climb in terms of quality. We had to figure out where the center of the onion was,” he says.
To find it, Kossnick and the team broadened the feedback group to the entire PM and design teams — their intended target persona.
This time, instead of using Slack threads, they made a giant FigJam board where they asked users for the same feedback: prompt, result, and scores. The infinite canvas proved great for collaboration and thought starters. “We got 1,000 examples of real things people wanted to build, use cases where the product fell over, places it did great and unexpected areas for each of these,” says Kossnick. “This shaped our features and designs.”
It was probably the most helpful day of the entire project.
These two groups of users were an onion-peeling exercise for Kossnick and the team. At its center, they identified the problem they wanted to solve for: designers, starting with designs, who wanted to bring these to life as prototypes. “Once we felt like there was a path on quality, we could invest a ton more in the whole product experience, its form factor, longtail features and workflows,” he says.
The next phase of feedback expanded company-wide, where the team hosted “The Great Figma Bakeoff,” which was a much larger version of the FigJam board they used with the PM and design teams. There were 15 in-person sessions across different timezones where people from around the world came together to create things using Make, get questions answered, record prompts and share use cases.
As the broadest group of potential users for Make, this showed the outer possibilities of the product — things Kossnick had no idea people would do. “We were optimizing for designers who’d start with a design and try to turn it into a prototype, but we got such a wider range of interest, engagement and success cases than we expected,” he says. Someone on the people team used an API to connect Figma Make to the company’s HR platform and made a game where you could guess people’s names and faces to get to know your colleagues. Someone on the sales team put together a microsite for an offsite. “My six year old made three video games in Figma Make,” says Kossnick.
Last to share feedback was a group of alpha testers composed of customers and external target personas. By this time, in-product feedback features had been added to the product — creating a more systematic and formalized assessment experience. But it was those internal FigJam feedback sessions that were most helpful, largely because of the speed to understanding what mattered and where to invest in the product further.
“It’s easy to over-engineer your eval stack, your data set, some part of the quality loop — but it all depends on what users want to use your product for,” says Kossnick. “Building conviction on where you want to invest is the key part to get right.”
3. Figure out how to assess the data you’ve gathered
Kossnick follows one simple rule to make sure evals are working: are we moving in the right direction? “What do you really want to test and what do you want the outcome to be?” he asks. When you’re looking at all the different product hills you can climb, there’s some intuition on determining the right one.
Even though he admits the initial data collection wasn’t the most sophisticated, it was extremely valuable — so he and the team had to figure out the best form factor in order to make it useful at scale.
Still focusing on product quality for a core persona (designers) and use case (designers bringing prototypes to life), Kossnick used four evaluation types:
Deterministic
Pretty straightforward, like a pass/fail class: did it do the thing or not?
While the benefit here is scalability, its scope is limited to things that can be judged as binary. For example, on Figma Design, those AI text boxes have a “shorten text” feature. You can very clearly see if the text was shortened. Another example is code generation. Could the AI-generated code actually run? Does it compile?
Kossnick implemented a script to assess these because they’re purely rooted in a yes/no answer.
Taste and judgement
Think about the text box example. Maybe the text was shortened — but was the shortened text actually good? This requires humans, and humans at scale, but the considerations are cost and speed.
There’s a different playbook being developed inside every product team right now about how to scale human taste.
Here’s where Kossnick and his team had to take all the qualitative feedback they were receiving and put it into some sort of structured dataset. Contractors and employees used an internal tool to track quality per different prompts, use cases and configurations throughout testing.
Every night, a team of contractors evaluated different versions of Figma Make — whether that was different system prompts or model choices like Claude vs. OpenAI — and log the results. The golden set of prompts they evaluated was initially built off the seed set from the company’s own dogfooding. When they received new scores back the next morning after each experiment, they could see which prompts progressed and regressed. Over time, they categorized both the scenarios (like, is this prompt supposed to result in an internal tool or a game?) and other modalities (does this start from a mockup or just a prompt?). “We wanted to make sure we had coverage and density for areas where we wanted to rigorously measure improvements,” says Kossnick.
These contractors used a Figma-created brand guide to evaluate the product’s quality, with examples of what made a good or bad form of a feature. “How do I explain to someone — who’s not just me, if I’m working on a bigger team and trying to scale up — what good looks like?” he says. This process is similar to how Google assessed search results using detailed training documents with hundreds of pages. Of course, your startup probably doesn’t need the Google-style, 100+ page booklet explaining evals to your raters. But if you’re a product at massive scale, and a 2% improvement in quality is a huge impact, you might consider it.
This feedback was used to see overall quality trajectory and resolve which internal experiments, branches and versions to move forward with while testing.
AI as judge
“Can you take human judgement and teach AI how to do it?” Kossnick says. “Depending on your task, this is either reasonably doable or not at all possible.”
In some cases, Figma was able to write a system prompt for an AI judge with examples and context for why a feature performed well, providing guidelines — then asking the AI to go and assess a number of its responses. “You’re getting into this meta-loop where you’re grading the graders,” he says. “You can double check its work, see what it’s saying is good or bad, and change the way it’s judging to try and scale up the work your human contractors are able to do.”
“That’s the appeal of some of the AI as judge playbooks you’re seeing come out of the industry,” Kossnick continues “What if you could evaluate every pull request or see every prompt change and how things improved? How tight can you get that loop?”
Usage analytics
A/B testing in production is also a form of evaluation. For example, does one model perform better than the other? You can have humans grading results internally as Figma did, but you can also take this framework external — with 50% of users on one model, and 50% on another. “We’re also running A/B tests on quality and features to help iterate faster,” says Kossnick.
A human-centered problem requires a human-centered solution
Every stage of Figma Make’s ideation, development and testing can be traced back to product experience — people use the product, and thus should play a large role in the evaluation of its quality. Kossnick was intentional about bringing Make’s target users into evals. While having designers and PMs turn concepts into prototypes is indicative of larger product development trends spurred by AI tooling, it also shows the human touch required to make a standout product.
“One of the worst things you can do in the quality loop is hill climb for a long time on something that’s not actually representative,” Kossnick says. “If you’ve been working in isolation and go out to users and their prompts are 30% different than yours, you’ve been optimizing for the wrong thing and need to start over again.”